Table of Contents
Once you have successfully processed the first part , you are well prepared to learn in this part how the individual components or. Now functions together.
Pre-certificate
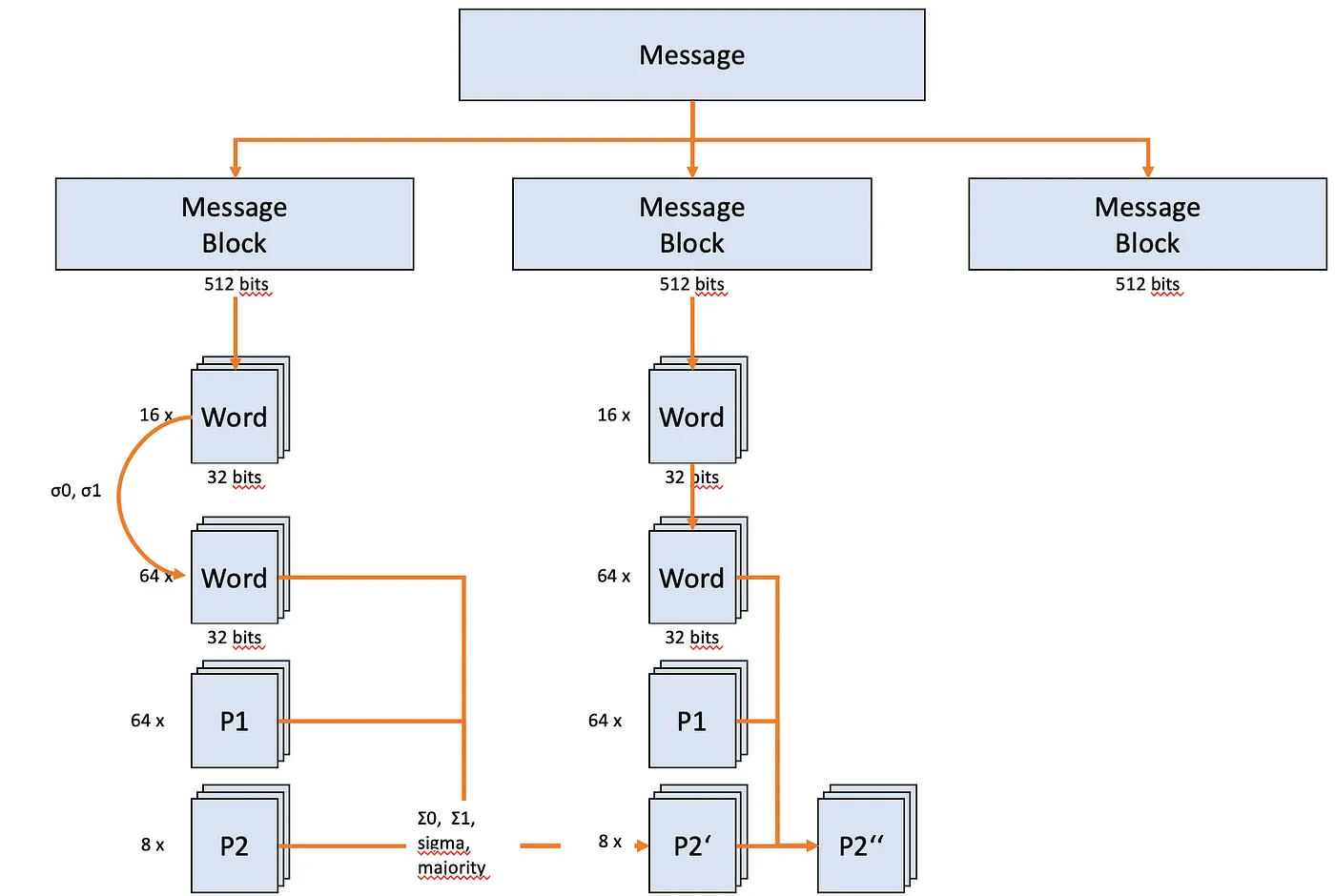
Before starting, I would like to clarify the connections again: We will immediately create a message (message), the length of which corresponds to a multiple of 512 bits; in the example, exactly 512 bit. The message is broken down into message blocks that are exactly 512 bit long. Each message block is in turn broken down into a message schedule, with 16 words (Words) of 32 bit length each. The length of the words must and will always be 32 bits! However, the message schedule is then extended to contain 64 words. Its length then: 2,048 bit. And graphically:
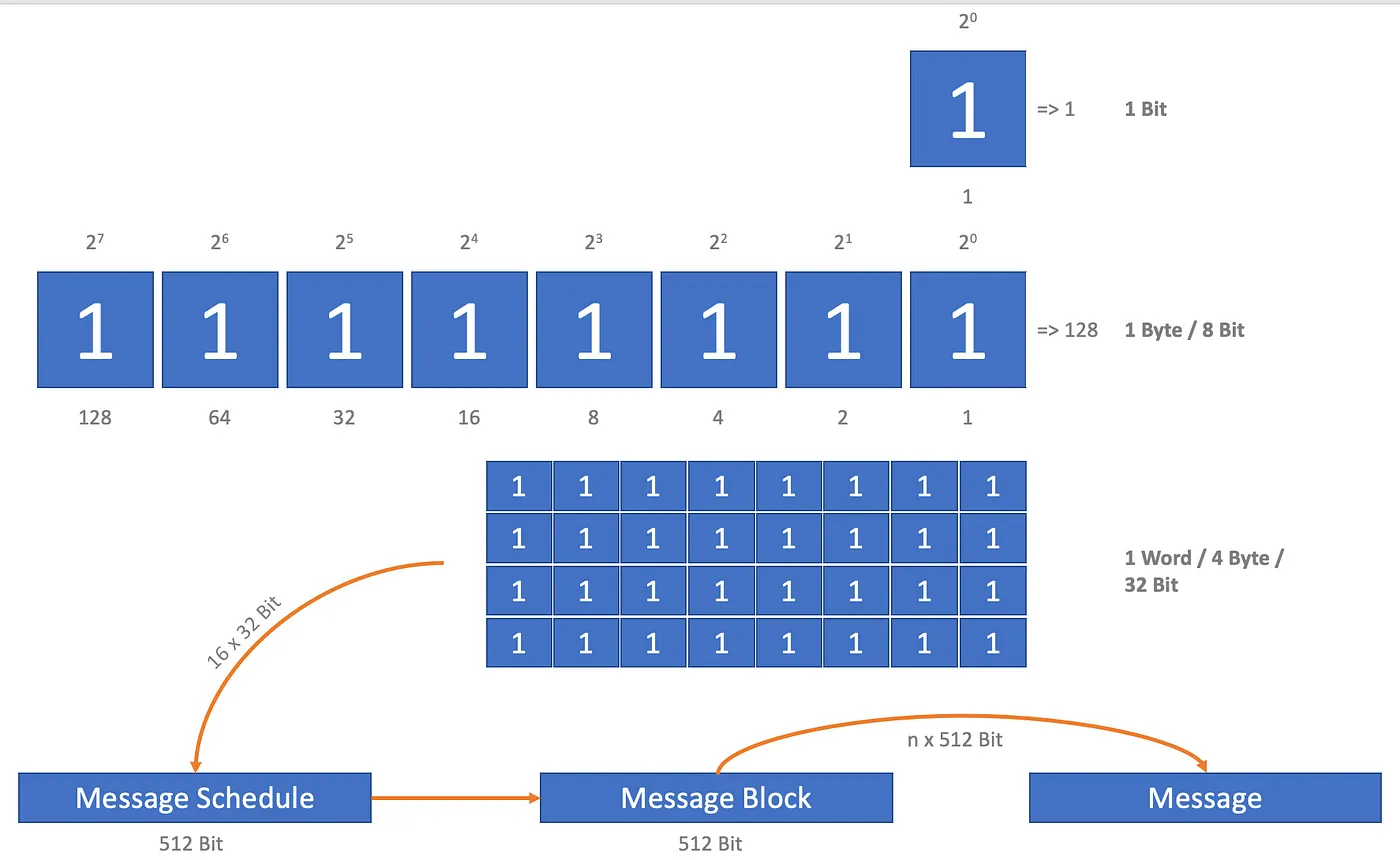
Important connections
Decompressions
So we want to calculate a SHA-256 -compliant checksum, the hash, from a message. To do this, the message, i.e. the string, must first be prepared. Our message is, clichéd:
1message = 'hello_world'
First we have to get the position in the character table for each letterd, i.e. convert the letters (or each character) into their numerical representation:
1dec_message = []
2for char in message:
3 dec_message.append(ord(char))
The achiedes is a list of integers:
1[104, 101, 108, 108, 111, 95, 119, 111, 114, 108, 100]
And since we had so much fun dealing with binary values in the first part, we convert the list into binary values that we simply link together:
1bin_message = ''
2for decimal in dec_message:
3 bin_message += '0' + bin(decimal)[2:
The result:
10110100001100101011011000110110001111110110110110110110110100100100100100
Here, however, there is a stumbling trap, and I am reluctant to leave it standing for, for which I have not yet found an explanation: in the transformation into the binary equivalent, we are putting ahead with every binary value ahead of everything. So 104 does not become 1101000 but 01101000, etc.
In addition, we attach 1 to this date, as a separator for what is now coming up.
Next we calculate the length of this binary number:
1len_bin_message = len(bin_message)
The length may or must be submitted exactly 64 bits. So we also convert it into a binary number to hang a few zeros at the front to get exactly 64 digits:
1rest_to_64 = 64 - len(bin(len_bin_message)[2:])
2bin_message_len = '0' * rest_to_64 + bin(len_bin_message)[2:]
Now we not only have to connect this three binary information, message, separating one and longitude, but also fill it with so many zeros, so that the total length is a multiple of 512.
1payload = bin_message + '1' + bin_message_len
2len_payload = len(payload)
3pad_string = int(512 - (len_payload % 512))
4full_message = bin_message + '1' + ('0' * pad_string) + bin_message_len
In our example, the three information shows 153 bits. So we have to include 359 zeros. Strictly speaking, there are between message and length specification. The result is always n 512 bits* long:
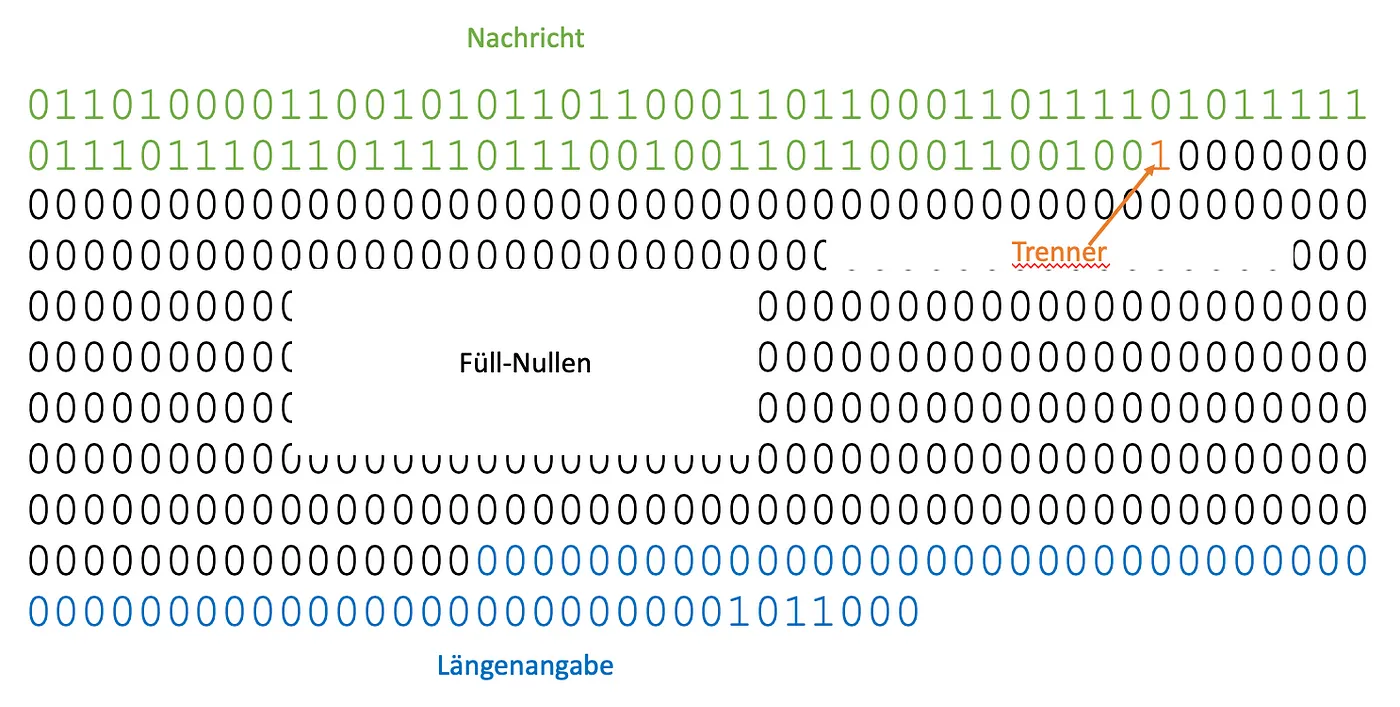
Setup of a pre-coded message
Last but not least, we take these very, very, very, very…very, very large number (it is very large, you should not see it as a number, but as a !) and divide it into so-called message blocks with a length of 512 bits each:
1message_block_length = 512
2message_blocks = [full_message[i:i+message_block_length] for i in range(0, len(full_message), message_block_length)]
Grab a coffee, go fresh air to get another shake out the chair. Now it starts.

The loop!
Since it is easier to explain the process without a loop, here is just a loop. You can still find the programmatic loop on Github .

Since our message is exactly 512 bit tall and we work without loop, we can go straight to the full: The laboriously glued message is now included in the so-called. Message Schedule disassembled: Speak in 16 words with 32 bit length each.
In the first run we take four words and make the following modifications:
- 1 is applied to word 1 at position 14,
- word 2 of position 9 remains unchanged,
- 0 is applied to word 3 at position 1 and
- Word 4 at position 0 remains unaffected
The values are added first and now there is another important point to consider: We must strictly ensure that the words are no longer than 32 bits. Because only in this way can we ensure that the final hash is always the same. And at the latest now, when adding large values, we can exceed the 32 bits quite quickly. From a technical point of view, this is also a hurdle. Therefore, here and for all additions we must finally use Modulo 2 32. And now the third hopefully positive kink comes in the learning curve: The binary universe also holds a nice simplification for Modulo: The logical And with 232–1 (or 4,494,967,295, that is a very large number, not as large as the one in the first part, but exactly one smaller counter) leads to the same result.
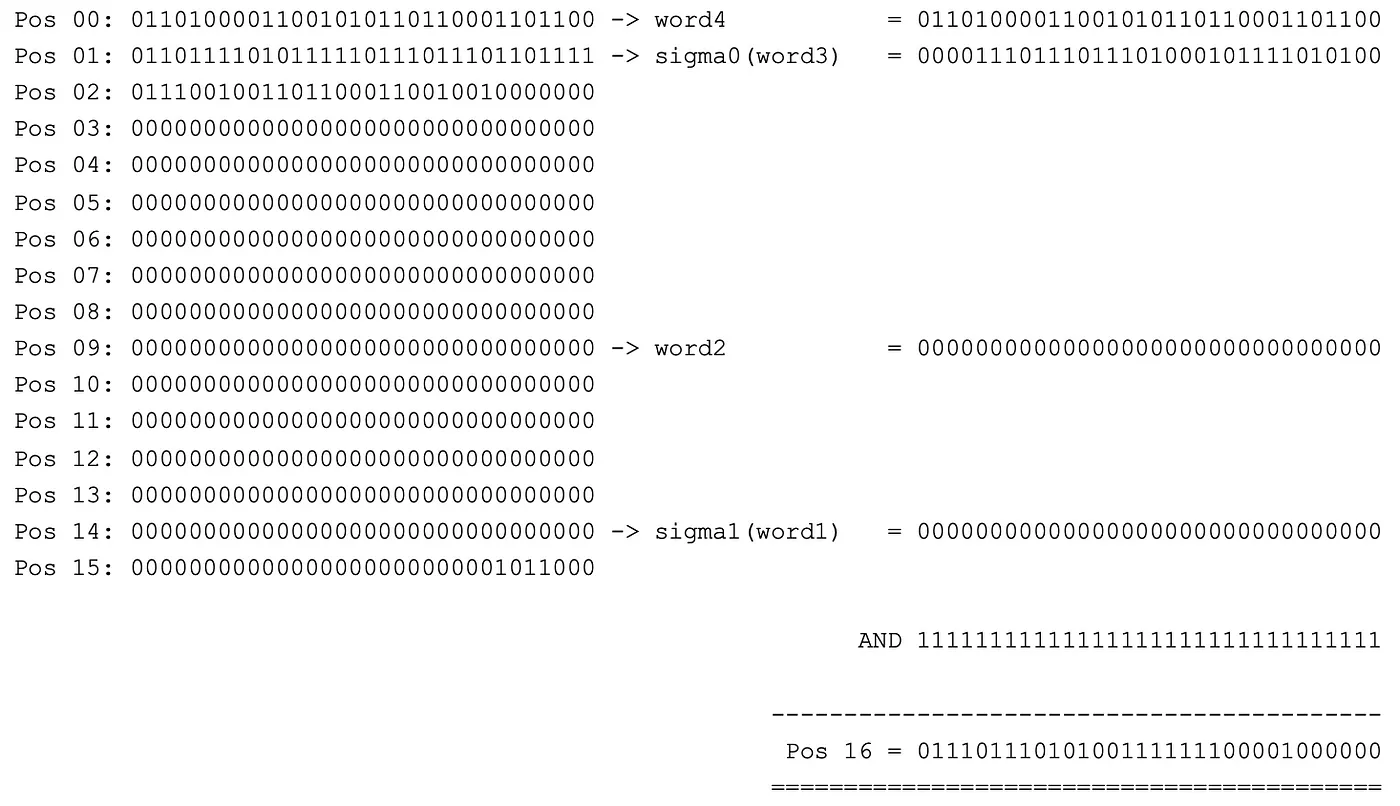
Calculation of the first step
This would prepare the message schedule and now contains 64 beautiful words of 32 bits each. So we first paided up the information from the Message Block and extended from 512 bit to 2,048 bit — but they are still readable:
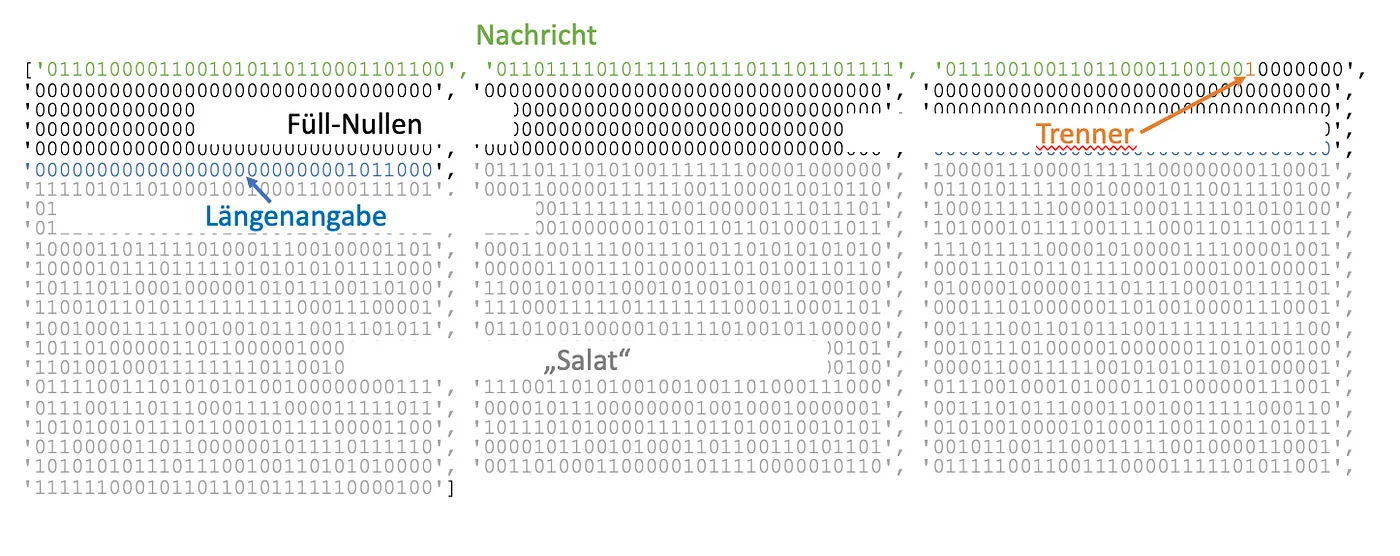
The extended Message Schedule
But that is now over, we are coming to the next and most important step:
The Compression
In this step, the extended message schedule is not modified directly, but the words are used as the basis for modifying the compression constants initially created.
In 64 loops runs we go through the message schedule. A new word is calculated from each word of the schedule (i.e. our original message) together with the 64 result constants and the 8 compression constants. The new word is then preceded by the compression constants, at the same time the last entry is deleted. This is how the list always contains exactly 8 entries.
1new_compression_constants = compression_constants.copy()for i, word in enumerate(message_schedule): term1 = (int(upper_sigma1(new_compression_constants[4]), 2) + \
2 int(choose(new_compression_constants[4], new_compression_constants[5], new_compression_constants[6]), 2) + \
3 int(new_compression_constants[7], 2) + \
4 int(result_constants[i], 2) + \
5 int(word, 2)) \
6 & int('11111111111111111111111111111111', 2) term2 = (int(upper_sigma0(new_compression_constants[0]), 2) + \
7 int(majority(new_compression_constants[0], new_compression_constants[1], new_compression_constants[2]), 2)) & int('11111111111111111111111111111111', 2) new_compression_constants.insert(0, 1)
8 new_compression_constants.pop() new_compression_constants[0] = bin(
9 (term1 + term2) & int('11111111111111111111111111111111', 2)
10 )[2:].zfill(32) new_compression_constants[4] = bin(
11 (int(new_compression_constants[4], 2) + term1) & int('11111111111111111111111111111111', 2)
12 )[2:].zfill(32)
First, a few calculations:
- Term 1 is calculated from the compression constants, one of the result constants and the respective word. We use here at bit level and Ã1 (upper sigma1) as well as choose.
- Term 2 is a sum of two other compression constants that are modified with the help of Ã0 (upper sigma0) and majority.
And now pay attention times that the original message part of the 1. Terms is marked in red in the picture:

In the first step, the calculation of two terms is performed
The two terms are now added (and, as always, brought to 32 bit course with Modulo 232) and placed at the beginning of the compression constants. The first term will also be held with the 4th Position of this now 9 words long list sums up:

In the second step, the list of compression constants is updated
Next, the last entry of the list is deleted, it now includes 8 completely new compression constants (if you have paid carefully, you will not have missed that they are not even that constant).
A part of the original message is now a portion of the original message as a summand of term 1 and the positions 0 and 4. These will slide part of the same calculations and keep down in the next runs. This distributes the original, previously half-way readable message, over the entire list.
This list is therefore the basis for the second run, which will “rotate” it again to create a completely new list for the third run. And so on until all 64 words of the message schedule are processed. The result should look something like this:
111100010000000010111101011011001
20100011011010010100000110100100
311100011111110010111100001001011
40111000110001000100010000011110
501001000000111100100000000011000100010001000
60001111111000110101100110101110101
711101001110010001101110111010100
80000100110110111100011011011
Or in Hexadecimal:
10xe2017ad9 0x46d28214 0xe3f9784b 0x7186041e 0x481e4018 0x1fc6b235 0xe9c8ddff4 0x96f0efb
Finally, this list will go through exactly this list of 8. Compression constants and add each position with the corresponding word of the source list:
1result = []for i in range(0, 8): result.append(
2 bin(int(compression_constants[i], 2) +
3 int(new_compression_constants[i], 2) &
4 int('11111111111111111111111111111111', 2))[2:].zfill(32))
And in plain text:

Last step: Adding the lists
The new list is now the source list for the next message schedule. However, since we do not implement the loop here, it was the first. The following is an example summary of the steps:
Schematic representation of the SHA-256 algorithm
Hashes. Health. What?
We did it. You did it. Congratulations.

Now we can either output the hash as a hex value or display it again in binary notation, depending on the purpose of the application.
1for word in result:
2 print(hex(int(word, 2))[2:].zfill(8) + '', end = '')
The result is impressive in any case.
135072c1ae546350e0bfa7ab11d49dc6f129e72cdec7eb671225bbd197c8f1
Or
11101010000011100101101101100010101000100011101101100011111111110100111110110100111010100111011011110110110110111100100111001110110110110110111111101111111110111111111111110001001000100101101110110101110101110101101110101101110101101101110001110110111110101101101101101101101110110110110110110110101
Epilog
You can find a complete implementation, including a loop to process even large messages , in this guest.
Of course, Python is not suitable for optimizing the SHA-256 process, but it is around to understand the process and learn how to deal with elementary binary computing operation.
If you want to understand the process in a more interactive way , I would like to recommend this video . There, the algorithm is reproduced in Ruby and the individual calculation steps are explained in more detail.
And why is SHA-256 so important for cryptocurrencies mining now? In short: The hash validates the validity of the cash book. Mining is about calculating exactly a given target hash from a given message and a freely selectable addition. The algorithm therefore has to be mad attenuated. Since this is very complex, it takes time and will be rewarded accordingly.
Summary
A detailed walkthrough of the SHA-256 algorithm, covering message preparation, the message schedule, and the compression function, with Python code examples to illustrate each step.
Main Topics: Python Cryptography SHA-256 Hashing Algorithms Data Security
Difficulty: intermediate
Reading Time: approx. 5 minutes