PHP - Mit welcher Methode durchsucht man ein Array am schnellsten?
Das schöne an PHP: Viele Wege führen nach Rom.
Das Problem mit PHP: Viele Wege führen nach Rom.
Denn diese Vielfallt stellt den Entwickler von Welt mituner vor eine schwierige Frage: Welcher Weg ist der kürzeste? Will man z.B. einen Wert (needle) in einem Array (haystack) suchen, gibt es in PHP zehn verschiedene Methoden. Du hast richtig gelesen: Zehn. Ich unterscheide einerseits auch die strikten und nicht-strikten Vergleiche, andererseits lasse ich die wirklich exotischen Methoden außen vor. Welche Methoden am schnellsten sind, werde ich versuchen im Folgenden herauszufinden. Außerdem schaue ich mir an ob es unter den letzten PHP-Versionen (7.0 bis 7.3*) Unterschiede in der Geschwindigkeit gibt.
* Genau genommen sind es PHP 7.0.33-1, PHP 7.1.26-1, PHP 7.2.14-1, PHP 7.3.1-3
Eins vorweg: Wenn du mit Schmalspur-Arrays arbeitest, die nur 12 Einträge enthalten, deren Werte nur ein ein Zeichen lang sind, kannst du hier gleich aussteigen. Du wirst schnell feststellen, dass sich Geschwindigkeitsvorteile erst bemerkbar machen, wenn die Arrays und ihre Werte länger werden.
Im folgenden Stelle ich die Methoden kurz vor. Dann beschreibe ich, wie ich die Messungen durchgeführt habe. Danach gibts das bunte Zahlenwerk, in dem ich erst die Methoden miteinander vergleiche und dann die PHP-Versionen.
tl;dr: in_array() und nicht strikter Vergleich schlägt alle anderen Methoden. Ende der Durchsage.
Welche Methoden gibt es, um ein Array nach einem Wert zu durchsuchen
array_search - strikt / nicht strikt
Diese Methode ist der klassische Weg. Array_search() durchsucht ein Array nach einem beliebigen Wert und liefert dann den dazugehörigen Schlüssel zurück. Ist der dritte Parameter auf TRUE gesetzt, erfolgt eine strikte Suche, bei dem nicht nur Inhalt sondern auch Typ überprüft werden (ein “typstarker Vergleich”).
in_array - strikt / nicht strikt
Diese Methode ist ähnlich zu der erst genannten. Allerdings wird hier nur ein Booleanscher Wert zurückgegeben, der anzeigt, ob der Wert im Array enthalten ist. Oder nicht. Auch in_array unterstützt typstarke Vergleiche.
foreach - strikt / nicht strikt
Natürlich hat man auch die Möglichkeit mit einer Schleife die Suche maximal zu individualisieren. Innerhalb der Schleife kann man beliebige Ereignise definieren und natürlich auch einen typstarken Vergleich anstellen. Ich habe die Schleife, für die Vergleichbarkeit, sehr einfach gehalten. Ist der Vergleich erfolgreich, wird die Schleife mit break; verlassen.
isset
Diese Methode ist eigentlich nicht das Mittel der Wahl, um ein Array nach einem Wert zu durchsuchen. Da ich aber sehen will, wie sich dieser Umweg im Vergleich schlägt, habe ich die Methode trotzdem mit aufgenommen. Zunächst nutze ich array_flip() um aus Schlüsseln Werte und vice versa zu machen. Dann kann ich mit isset() prüfen, ob der Schlüssel sprich der ehemalige Wert vorhanden ist.
Dazu muss gesagt werden, dass diese Methode ansich sehr schnell sein kann. Wenn der Anwendungsfall es zulässt, dass du deine Daten als Schlüssel und nicht als Wert in einem Array ablegst, solltest du diese Funktion bevorzugen! Das klappt natürlich nicht, wenn du mit NULL-Werten oder nicht uniquen Werten arbeitest!
array_intersect
Auch das ist ein Exot, der für diese Zwecke eigentlich wenig sinnvoll ist. Was nicht heißt, dass es auch hierfür Anwendungsfälle geben kann. Mit array_intersect() wird eine Teilmenge von zwei Arrays erzeugt. Ich übergebe die zu suchende needle als Array und bilde die Teilmenge mit dem haystack. Ist das Ergebnis-Array größer als 0, enthält der Heuhaufen die Nadel. Der Vorteil: Sucht man mehr als eine Nadel, kann man mit der Schnittmenge sehr gut weiterarbeiten. Von dieser Methode gibt es einige verrückte Abwandlungen, die ich hier aber nicht alle getrennt betrachten möchte.
array_keys - strikt / nicht strikt
Der nächste Exot in dieser Reihe ist array_keys(). Hier kann man ebenfalls einen striken typsicheren Vergleich anstrengen. Die Methode arbeitet ähnlich wie array_intersect(), liefert jedoch eine Teilmenge der Schlüssel zurück, die den gesuchten Wert enthalten. Auch dieser Weg ist eigentlich ein Umweg der nur in bestimmten Situationen anwendbar.
Methodik und Testaufbau
Um der ganzen Sache wenigstens einen blassen wissenschaftlichen Anstrich zu verpassen, will ich das Vorgehen kurz erläutern. Der Quellcode ist auf github.com verfügbar.
Ich habe etwa 10.000 Arbeitsstunden in einer sehr ausgeklügeltes PHP-Script investiert. Dieses Script erzeugt ein zufälliges Array mit einer vorgegeben Länge an Keys (initArrayLength) und füllt dieses mit Werte, die eine vorgebene Länge haben (arrayValueLengths). Die Länge des Arrays kann zur Laufzeit erhöht werden, indem eine Potenz (maxPowers) angwendet wird. Danach wird dieses Array mit der angegeben Methode durchsucht (lookupMethod). Die Anzahl der Suchvorgänge wird mit maxIterations angegeben. Ist forceNewRandomArray auf 1 (aka TRUE) gesetzt, wird nach jedem Durchgang ein neues Array erzeugt.
Um die in PHP eingebaute “static optimization” zu umgehen, gibt es den Parameter disableOptimization. Ist dieser mit 1 aktiviert, wird vor jedem Aufruf ein sleep(0); abgesetzt. Das verzögert den Programmablauf nicht, blockiert aber dieses Feature. Für die Messung habe ich den Parameter stets deaktiviert.
Außerdem lässt sich mit forceNewRandomArray = 0 festlegen, dass das Array nicht bei jedem Durchlauf neu erzeugt wird. Das beschleunigt die Laufzeit bei großen Arrays erheblich.
Die needle, also der zu suchende Wert, befindet sich immer am Ende des Arrays.
Die Zeitmessung wird mit microtime(true); vorgenommen. Diese Methode erlaubt eine mikrosekunden-genaue Messung. So sieht beispielhaft die Implementierung für die Methode in_array() aus:
private function useInArray($strictMode) {
$startTime = microtime(true);
if ($this->disableOptimization) {sleep(0);}
$result = in_array($this->needle, $this->haystack, $strictMode);
$endTime = microtime(true);
$this->currentResults['delay'] = number_format(($endTime - $startTime), 25, ",", ".");
$this->currentResults['memory_usage'] = memory_get_usage(true);
Das ganze Script wird in der Kommandozeile ausgeführt. Pro-Tipp: In einer Screen-Session! Ein Beispiel-Aufruf sieht demnach so aus:
php-cgi7.0 -q compareLookups.php initArrayLength=10 arrayValueLengths=1,10,50,100 maxPowers=5 maxIterations=1000 forceNewRandomArray=1 breakAfterFound=1 disableOptimization=0 lookupMethod=in_array phpVersion=7.0 comment=initial_comparison
Damit das ganze automatisiert und für alle Methoden einmal aufgerufen wird habe ich diese Zeile etwas abgewandelt in ein Shell-Script gepackt und dieses Script dann ausgeführt. Das Shell-Script gibt es ebenfalls bei github - siehe oben. Die ganze Chose läuft auf einem virtuellen self-managed Server, der mit Ubuntu 16.04 betrieben wird. Die Kiste hat acht Kerne mit jeweils einer Intel Xeon CPU E5-2680 v3 @ 2.50GHz und 16 GByte RAM.
Ich habe Arrays mit einer Länge von 10, 100, 1.000, 10.000 und 100.000 Schlüsseln untersucht, die jeweils Werte mit einer Länge von 1, 10, 50, 100 Zeichen enthalten. Jede Variation wurde mit jeder Methode 1.000 mal gemessen. Insgesamt habe ich so 800.000 mal Arrays durchsucht, oder: Je Methode 80.000 Durchläufe.
Ergebnisse
Zunächst zur Übersicht des Gesamtergebnisses in Abbildung 1 und 2: Die durchschnittliche Dauer in Mikrosekunden über alle Durchläufe hinweg. Die Länge der Arrays wirkt sich überproportional auf die Dauer aus. Das fällt vor allem bei array_intersect() auf: Ein Array mit 10.000 Schlüsseln benötigt durchschnittlich 2,479 ms, bei 100.000 Schlüsseln sind es 38,572 ms. Anders bei zunehmender Größe der Werte: Steigen dies um den Faktor 10 (10 Zeichen bzw. 100 Zeichen je Wert), dauert die Suche im Schnitt nicht mal 2 ms länger.
-
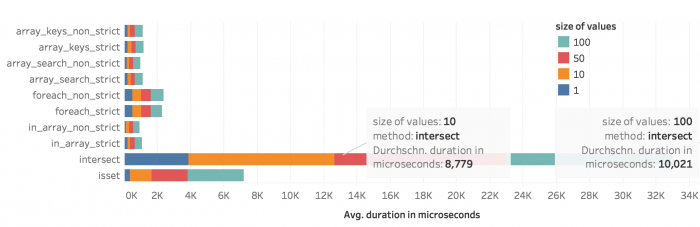
Durchschnittliche Dauer in Mikrosekunden je Methode
-
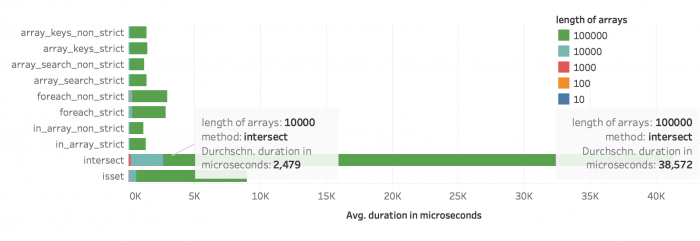
Durchschnittliche Dauer in Mikrosekunden je Methode


Die folgenden Abbildungen 3 bis 7 zeigen die exakten Messwerte für alle Methoden.
-
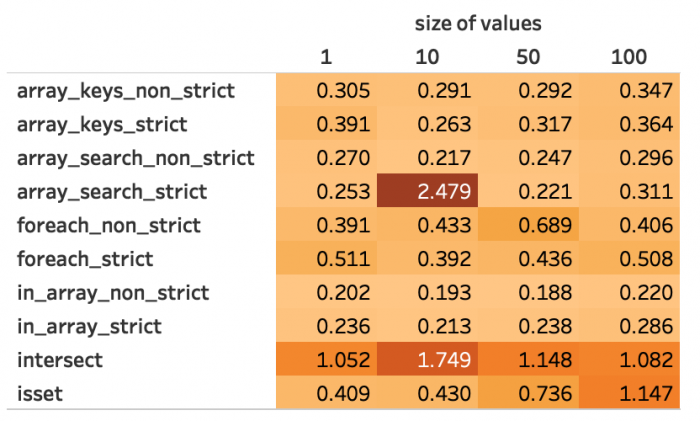
Abbildung 3: Durchschnittliche Dauer bei 10 Schlüsseln
-
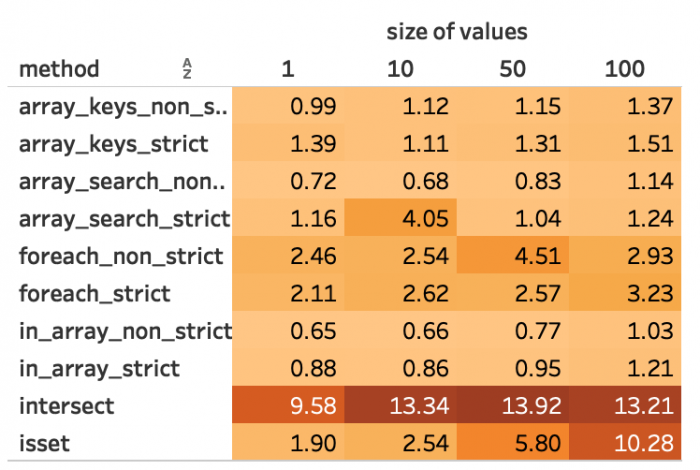
Abbildung 4: Durchschnittliche Dauer bei 100 Schlüsseln
-
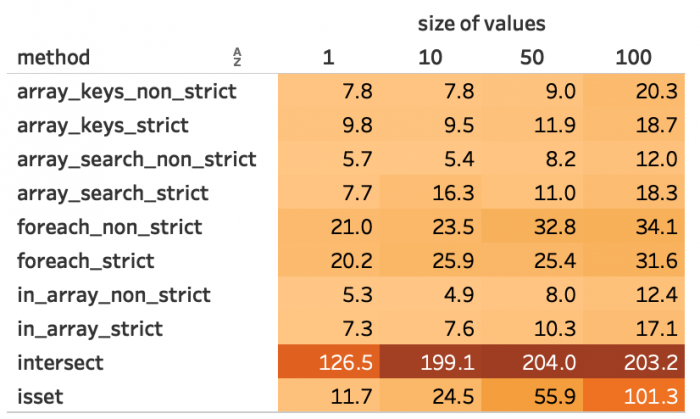
Abbildung 5: Durchschnittliche Dauer bei 1.000 Schlüsseln
-
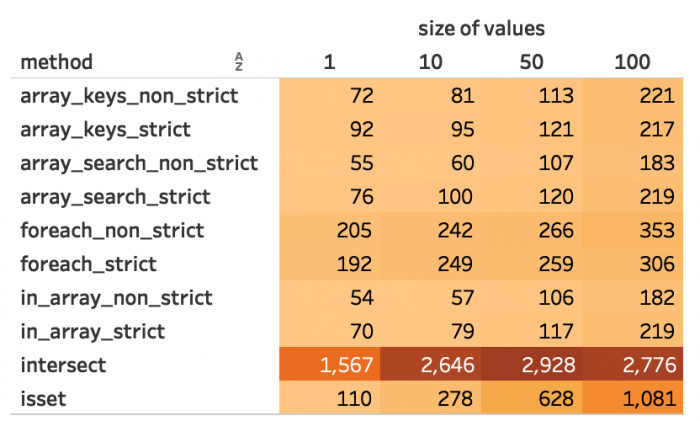
Abbildung 6: Durchschnittliche Dauer bei 10.000 Schlüsseln
-
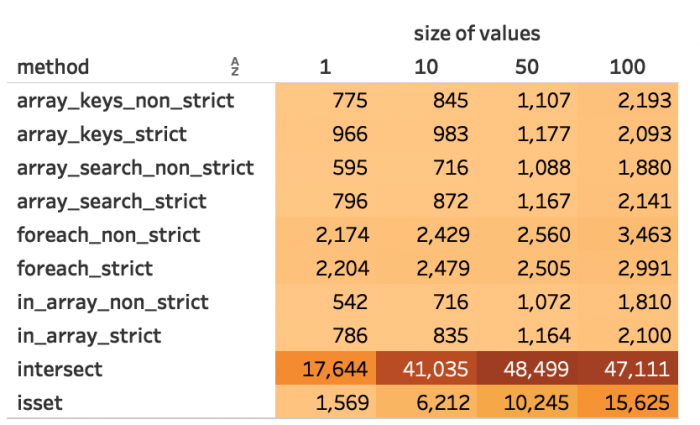
Abbildung 7: Durchschnittliche Dauer bei 100.000 Schlüsseln





Zur bessern Übersicht zeigen die folgenden beiden Abbildungen die Messungen ohne array_intersect(). Man sieht, dass isset() bei Werten mit einer Länge von 1 zumindest bei der foreach-Schleife mithalten kann. Ob der strikte Vergleich ein Nachteil ist, kann man schwer sagen. In der foreach-Schleife ist der strikte Vergleich minimal schneller, die anderen Methoden sind mit dem strikten Vergleich etwas langsamer. Tendentiell scheint non strict aber immer etwas schneller zu sein, wenn auch nur wenige Mikrosekunden.
-
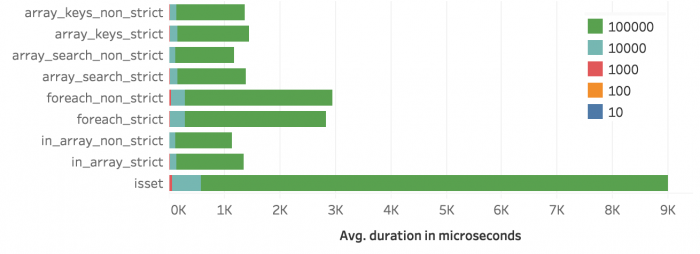
Abbildung 12: Durchschnittliche Dauer ohne array_intersect()
-
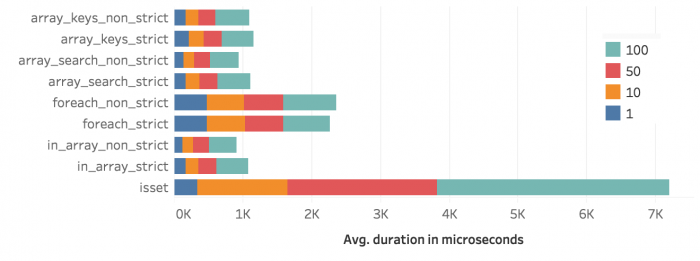
Abbildung 11: Durchschnittliche Dauer ohne array_intersect()


Wie machen sich die aktuellen PHP-Versionen im Vergleich? Das zeigt Abbildung 13**. Im Vergleich zu PHP 7.0 bringen Version 7.1 und 7.3 einen Geschwindigkeitsschub**. Nicht jedoch PHP 7.2, hier waren die Durchläufe im Schnitt viel langsamer als unter PHP 7.0. Am auffälligsten sind die Auswirkungen bei der foreach-Schleife. PHP 7.3 sorgt hier durchschnittlich 25% schnellere Durchläufe.

Abbildung 13: Veränderung der durchschnittlichen Dauer je Methode und PHP-Version.
Ähnlich geht es beim Speicherverbrauch zu. Hier tut sich erst mit PHP 7.3 einiges, der Verbrauch sinkt um knapp 25%!
Fehlerquellen
Die gibt es. Zum einen meine zauberhafte Implementierung des Scripts. Wer weiß, ob mir da nicht irgendwo ein Fehler untergelaufen ist. Außerdem meine vielleicht etwas lasche Interpretation der Ergebnisse. Statistik war zwar Teil meines Studiums, aber erstens ist das lange her und zweitens hatte ich an dem Tag einen starken Kater. An die Party dazu kann ich mich in Teilen gut erinnern, die Vorlesung ist wie ausgelöscht.
Außerdem sollte erwähnt werden, dass ich den Server nebenbei auch als öffentlichen Web-Server benutze (allerdings ohne nennenswerte Auslastung). Die Messung habe ich deshalb nachts ausgeführt. Ich gehe aber trotzdem davon aus, dass die meisten Ausreißer auf dieses Setup zurückzuführen sind.
Ausreißer
Davon gibt es eine Menge. Die Ursache sind mannigfaltig und schwer nachvollziehbar. Ich habe hier nicht viel wissenschaftlichen Aufwand betrieben sondern nur die augenscheinlichen Fehlmessungen entfernt. Die folgenden Abbildungen sollen beispielhaft zeigen, wie oft und offensichtlich Ausreißer aufgetreten sind.
-

Abbildung 8: Ausreißer
-
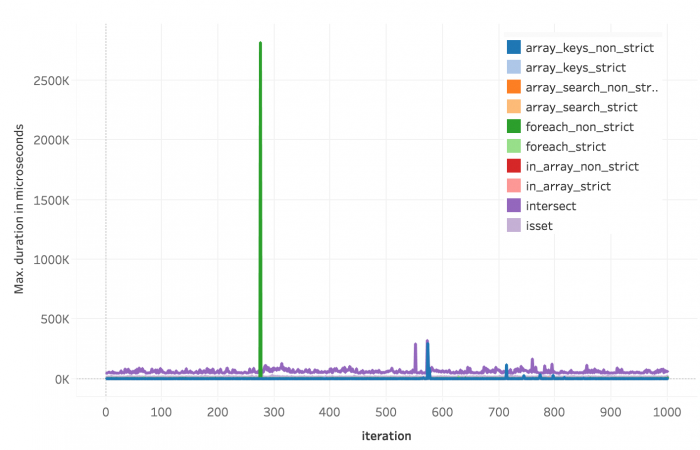
Abbildung 9: Durchschnittliche Dauer je Methode
-
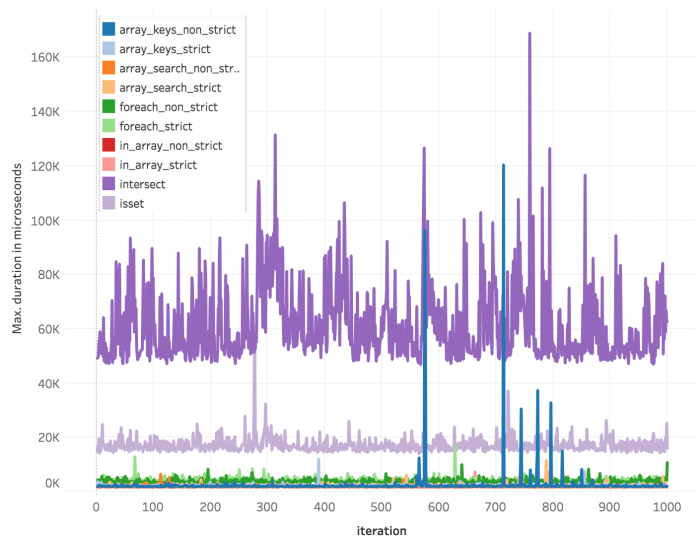
Abbildung 10: Durchschnittliche Dauer je Methode, bereinigt



Static Optimization
Wenn man sich die Ergebnisse einmal anschaut, fällt etwas auf: Obwohl microtime() mit einer sehr hohen Genauigkeit misst, scheinen manche Methoden bereits nach 0 Sekunden fertig zu sein. Der Grund dafür dürfte einerseits natürlich die Hardware und andererseits die static optimization sein. Das Feature übersteigt meinen Kompetenzbereich leider bei weitem, deswegen kann ich nur laienhaft daherplappern:
- Mit sleep(0); innerhalb der Zeitmessung (siehe auch oben) kann man dieses Feature ausbooten.
- Und außerdem scheint es eine Art unteres Limit für diese “schnellste Zeit” zu geben. So gibt es Messungen mit größeren Arrays, die exakt die gleiche Dauer aufweisen: 0,000000953674 Sekunden. Wird das Array noch größer, dauert es sogar exakt doppelt so lang, nämlich 0,000001907349 Sekunden. Diese Reihe kann man in Grenzen weiterführen. Zufall? Fragen! Wer dazu eine fundierte Erklärung hat, kann das gerne in den Kommentaren mitteilen.
Die folgenden Abbildungen zeigen die Häufigkeiten der unterschiedlicher Messwerte bis 10 Mikrosekunden. Auch hier ist noch mal interessant zu beobachten, wie die Messungen der Durchläufe kaum voneinander abweichen.
-
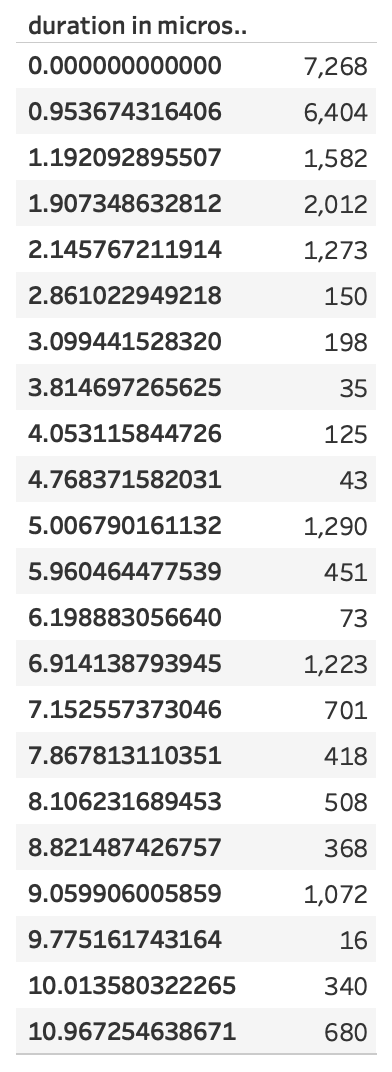
Abbildung 14: Verteilung der Messwerte für alle Messungen
-
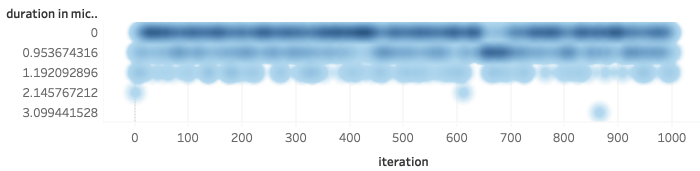
Abbildung 15: Verteilung der Messwerte für die foreach-Schleife (nicht strikter Vergleich)


Fazit
Grundsätzlich sollte man eines nicht vergessen: Die Messungen finden im Mikrosekundenbereich statt. Selbst die langsamste Methode array_intersect() hat für große Arrays nur 120 Mikrosekunden benötigt, im Schnitt liegt die Dauer bei etwa 8 Millisekunden. Auch große Arrays (100.000 Schlüssel, 100 Zeichen je Wert) waren im Schnitt nach 45 Millisekunden abgefertigt. Soviel zu den subjektiven, absoluten Zahlen, die abhängig von den Begleitumständen natürlich weitaus schlechter aussehen können.
Im Vergleich mit allen anderen Methoden ist array_intersect() absolut keine Wahl. Isset() kann unter bestimmten Bedingungen tatsächlich das Mittel der Wahl sein (siehe oben), verliert im direkten Vergleich aber.

Abbildung 16: Durchschnittliche Dauer insgesamt je Methode
Interessant ist, dass der nicht strikte Vergleich insgesamt etwas schneller ist - außer bei der Verwendung der foreach-Schleife! Diese ist allerdings grundsätzlich fast doppelt so langsam wie die anderen Methoden. Und diese liegen fast immer gleich auf so das man sagen kann, dass es hier keine Präferenz gibt.

Abbildung 17: Durchschnittliche Dauer insgesamt der schnellsten Methoden.
Um es mit den Worten einer weisen Philosophin zu sagen: “Ich kann Dir nur die Tür zeigen. Hindurchgehen musst Du alleine”. Nutze die Erkenntnisse dafür, die richtige Methode für den richtigen Zweck zu wählen. Du weißt nun, mit welcher Methode man einen großen Array in PHP optimal durchsuchen kann. Und nebenbei hast du vielleicht noch gelernt, welche Methoden es überhaupt gibt. Wenn dich das glücklich macht, habe ich mein Ziel erreicht.